放送大学「心理統計法(‘17)」第5章 第6章 その1
授業ではrstanパッケージを使ってますが、MCMCpackパッケージを使ってみます。初学者ですので間違いが多々あると思います。
(Rスクリプトはここ)
早稲田大学文学部文学研究科 豊田研究室
(参考)
ベイジアンMCMCによる統計モデル
Using the ggmcmc package
Bayesian Inference With Stan ~番外編~
Exercise 2: Bayesian A/B testing using MCMC Metropolis-Hastings
政治学方法論 I
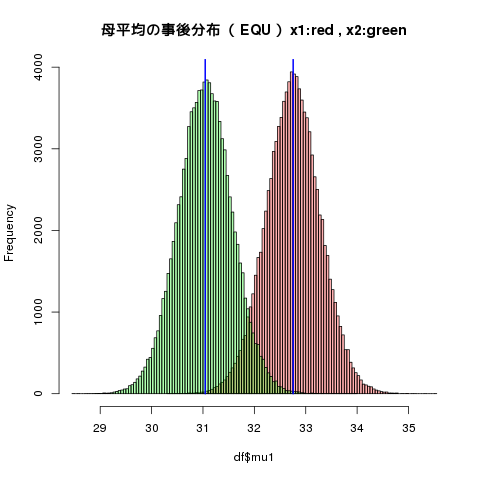
標準偏差が共通するモデル(EQU)
|
|
Iterations = 2001:201991
Thinning interval = 10
Number of chains = 5
Sample size per chain = 20000
Empirical mean and standard deviation for each variable,
plus standard error of the mean:Mean SD Naive SE Time-series SE
[1,] 32.755 0.5304 0.0016773 0.002084
[2,] 31.044 0.5299 0.0016756 0.002077
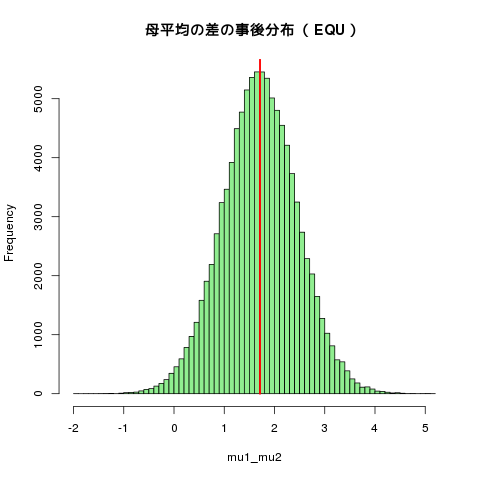
[3,] 2.351 0.2812 0.0008892 0.001196Quantiles for each variable:
2.5% 25% 50% 75% 97.5%
[1,] 31.707 32.404 32.756 33.105 33.802
[2,] 29.999 30.695 31.045 31.395 32.092
[3,] 1.878 2.152 2.324 2.519 2.976
|
|
Potential scale reduction factors:
Point est. Upper C.I.
[1,] 1 1
[2,] 1 1
[3,] 1 1
Multivariate psrf
1
|
|
var1 var2 var3
64832.32 65093.17 55375.97
data.frame 作成、テキストにあわせた出力にするためにdata.frame ryou を作成
|
|
確率:mu1>mu2 : mu2>mu1 ; mu1-mu2>1
|
|
[1] 0.98817
|
|
[1] 0.01183
|
|
[1] 0.83177
|
|
|
|
事後予測分布
|
|
| EAP | post.sd | 2.5% | 5% | 50% | 95% | 97.5% | |
|---|---|---|---|---|---|---|---|
| mu1 | 32.76 | 0.53 | 31.71 | 31.88 | 32.76 | 33.63 | 33.80 |
| mu2 | 31.04 | 0.53 | 30.00 | 30.17 | 31.05 | 31.91 | 32.09 |
| sigma | 2.35 | 0.28 | 1.88 | 1.94 | 2.32 | 2.85 | 2.98 |
| mu1_mu2 | 1.71 | 0.75 | 0.24 | 0.49 | 1.71 | 2.94 | 3.18 |
| x1aste | 32.76 | 2.42 | 27.97 | 28.79 | 32.76 | 36.71 | 37.53 |
| x2aste | 31.04 | 2.43 | 26.23 | 27.05 | 31.05 | 35.01 | 35.82 |
効果量
|
|
EAP post.sd 2.5% 5% 50% 95% 97.5%
0.738 0.326 0.096 0.200 0.738 1.278 1.373
|
|
TRUE
0.95
非重複度
|
|
EAP post.sd 2.5% 5% 50% 95% 97.5%
0.759 0.098 0.538 0.579 0.770 0.899 0.915
|
|
TRUE
0.57709
優越率
直接比較
|
|
TRUE
0.69458
事後分布から
|
|
EAP post.sd 2.5% 5% 50% 95% 97.5%
0.694 0.079 0.527 0.556 0.699 0.817 0.834
|
|
TRUE
0.25565
閾上率
|
|
TRUE
0.58576
|
|
EAP post.sd 2.5% 5% 50% 95% 97.5%
0.584 0.086 0.411 0.439 0.586 0.721 0.744
|
|
TRUE
0.02037
「MCMCpack」でWAICを求める
以下は「linux」で行った方法です
この部分のコメントアウト # を取り除く
|
|
WAICを求めるためには対数尤度が必要ですが、「MCMCpack」では対数尤度を返り値に加える方法がわかりません。(いまのところできない?)
しかし、パラメータ verbose=数値 を指定すれば、function value = -195.02600 と対数尤度が表示されます。
画面表示される代わりに
sink関数を使ってファイルに保存
-> 不要な行等を削除(gawkを使いました)し、ファイルに保存
-> scan関数でRに対数尤度を取り込み
-> chain行のmatrixに変換
-> burnin期間の行を削除
-> 1列のmatrixに変換してloo::waic に入力
(注) thin=verbose , burnin=thin*整数 とすること
で、結果は