放送大学「心理統計法(‘17)」第5章 第6章 その2
授業ではrstanパッケージを使ってますが、MCMCpackパッケージを使ってみます。初学者ですので間違いが多々あると思います。
(Rスクリプトはここ)
早稲田大学文学部文学研究科 豊田研究室
(参考)
ベイジアンMCMCによる統計モデル
Using the ggmcmc package
Bayesian Inference With Stan ~番外編~
Exercise 2: Bayesian A/B testing using MCMC Metropolis-Hastings
政治学方法論 I
(前回の記事)
心理統計法(‘17) その2 放送大学「心理統計法(‘17)」第5章 第6章 その1
標準偏差が異なるモデル(DEF)
|
|
Iterations = 2001:201991
Thinning interval = 10
Number of chains = 5
Sample size per chain = 20000
Empirical mean and standard deviation for each variable,
plus standard error of the mean:Mean SD Naive SE Time-series SE
[1,] 32.753 0.5897 0.001865 0.002524
[2,] 31.042 0.5163 0.001633 0.002219
[3,] 2.590 0.4612 0.001458 0.002287
[4,] 2.276 0.4054 0.001282 0.002013Quantiles for each variable:
2.5% 25% 50% 75% 97.5%
[1,] 31.584 32.370 32.754 33.137 33.918
[2,] 30.024 30.707 31.040 31.376 32.067
[3,] 1.874 2.265 2.529 2.846 3.661
[4,] 1.643 1.989 2.221 2.503 3.221
|
|
Potential scale reduction factors:
Point est. Upper C.I.
[1,] 1 1
[2,] 1 1
[3,] 1 1
[4,] 1 1
Multivariate psrf
1
|
|
var1 var2 var3 var4
54612.12 54288.77 40756.98 40936.99
|
|
|
|
[1] 0.98335
|
|
[1] 0.01665
|
|
[1] 0.82206
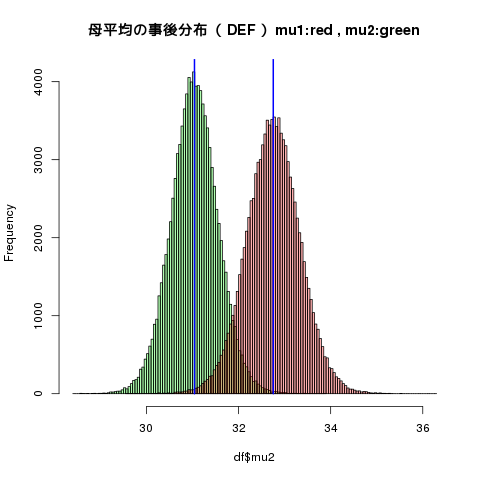
sdの小さい mu2 を先に描く
|
|
|
|
|
|
| EAP | post.sd | 2.5% | 5% | 50% | 95% | 97.5% | |
|---|---|---|---|---|---|---|---|
| mu1 | 32.75 | 0.59 | 31.58 | 31.79 | 32.75 | 33.72 | 33.92 |
| mu2 | 31.04 | 0.52 | 30.02 | 30.20 | 31.04 | 31.89 | 32.07 |
| sigma1 | 2.59 | 0.46 | 1.87 | 1.96 | 2.53 | 3.44 | 3.66 |
| sigma2 | 2.28 | 0.41 | 1.64 | 1.72 | 2.22 | 3.02 | 3.22 |
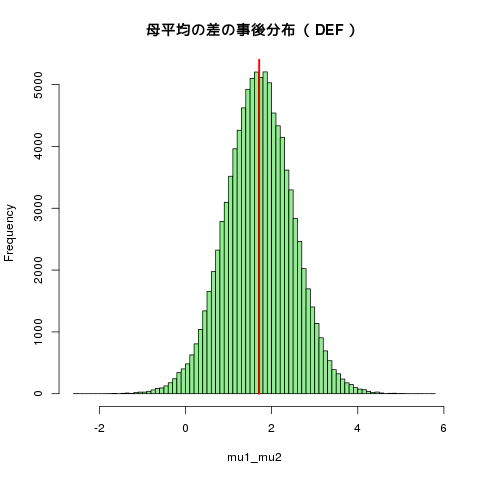
| mu1_mu2 | 1.71 | 0.78 | 0.16 | 0.43 | 1.71 | 2.99 | 3.25 |
| x1aste | 32.75 | 2.69 | 27.42 | 28.35 | 32.76 | 37.16 | 38.08 |
| x2aste | 31.06 | 2.37 | 26.38 | 27.20 | 31.05 | 34.91 | 35.76 |
効果量
|
|
EAP post.sd 2.5% 5% 50% 95% 97.5%
0.681 0.327 0.059 0.160 0.674 1.231 1.345
|
|
EAP post.sd 2.5% 5% 50% 95% 97.5%
0.774 0.374 0.067 0.182 0.764 1.407 1.543
|
|
TRUE
0.9341
|
|
TRUE
0.94462
非重複度
|
|
EAP post.sd 2.5% 5% 50% 95% 97.5%
0.766 0.107 0.527 0.572 0.778 0.920 0.939
|
|
EAP post.sd 2.5% 5% 50% 95% 97.5%
0.741 0.100 0.523 0.563 0.750 0.891 0.911
|
|
TRUE
0.59707
|
|
TRUE
0.49877
優越率
直接比較
|
|
TRUE
0.68667
事後分布から
|
|
EAP post.sd 2.5% 5% 50% 95% 97.5%
0.687 0.081 0.517 0.548 0.692 0.811 0.831
|
|
TRUE
0.22758
閾上率
直接比較
|
|
TRUE
0.57793
事後分布から
|
|
EAP post.sd 2.5% 5% 50% 95% 97.5%
0.580 0.086 0.407 0.436 0.583 0.718 0.742
|
|
TRUE
0.01953