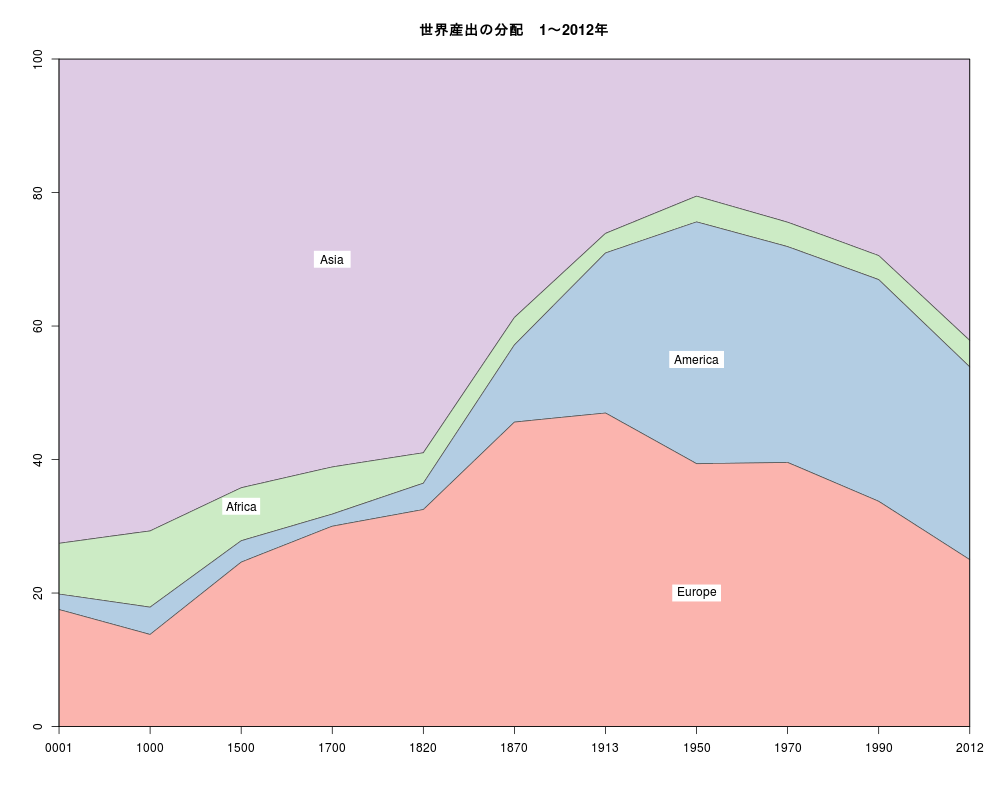
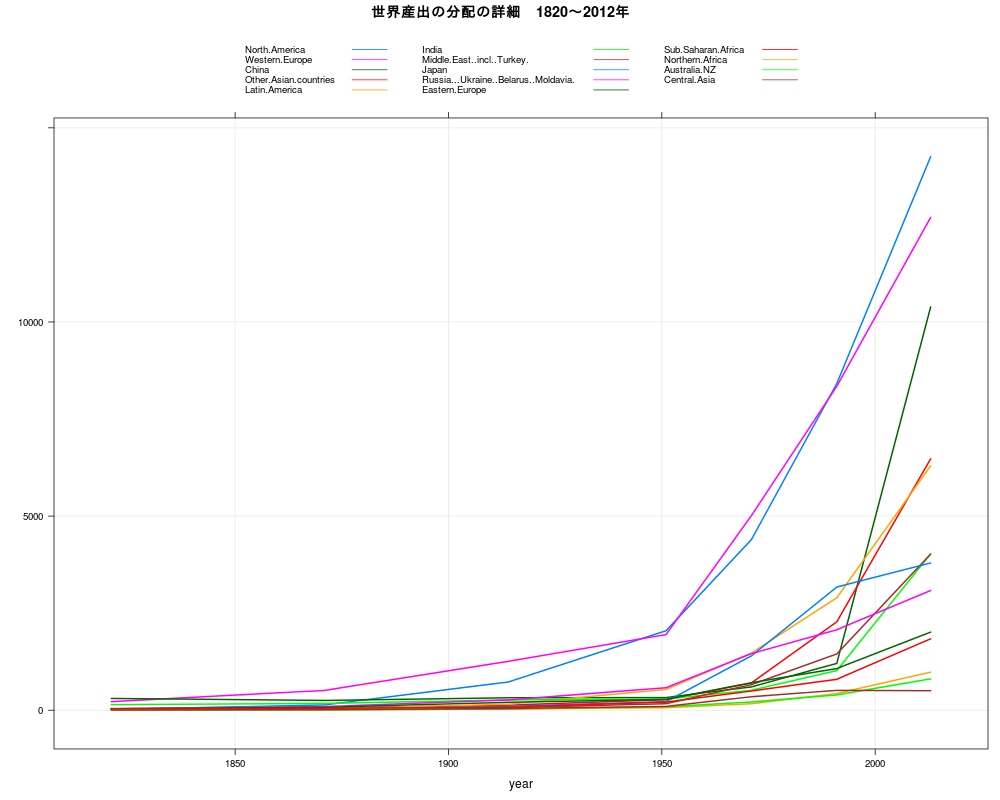
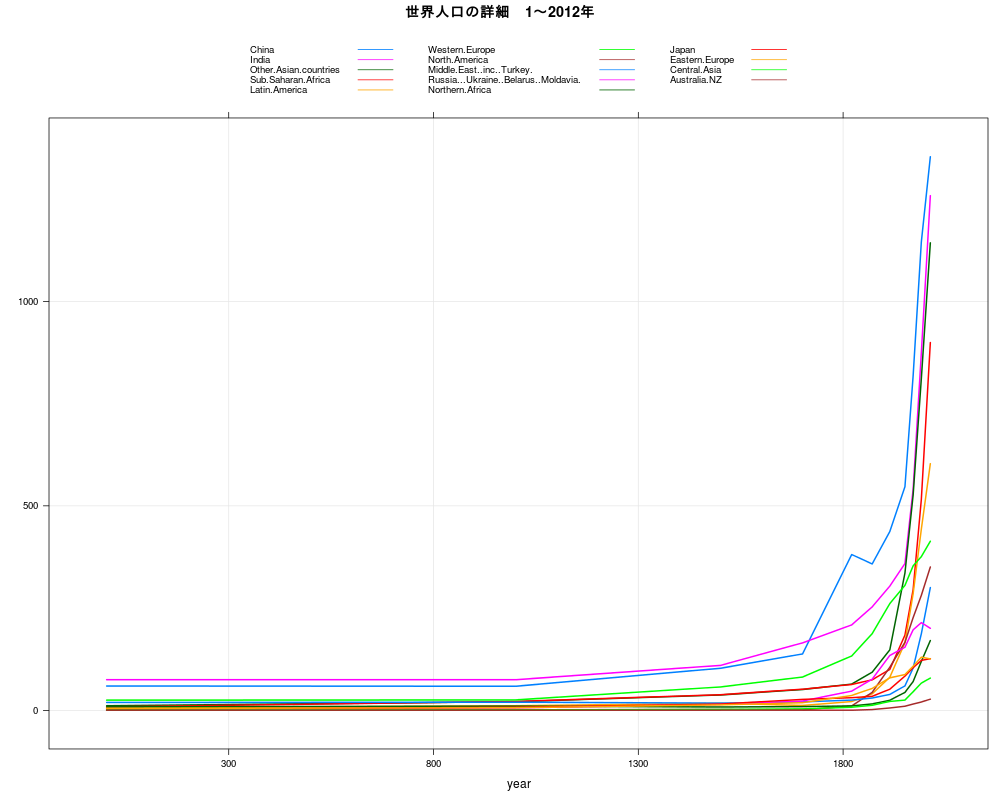
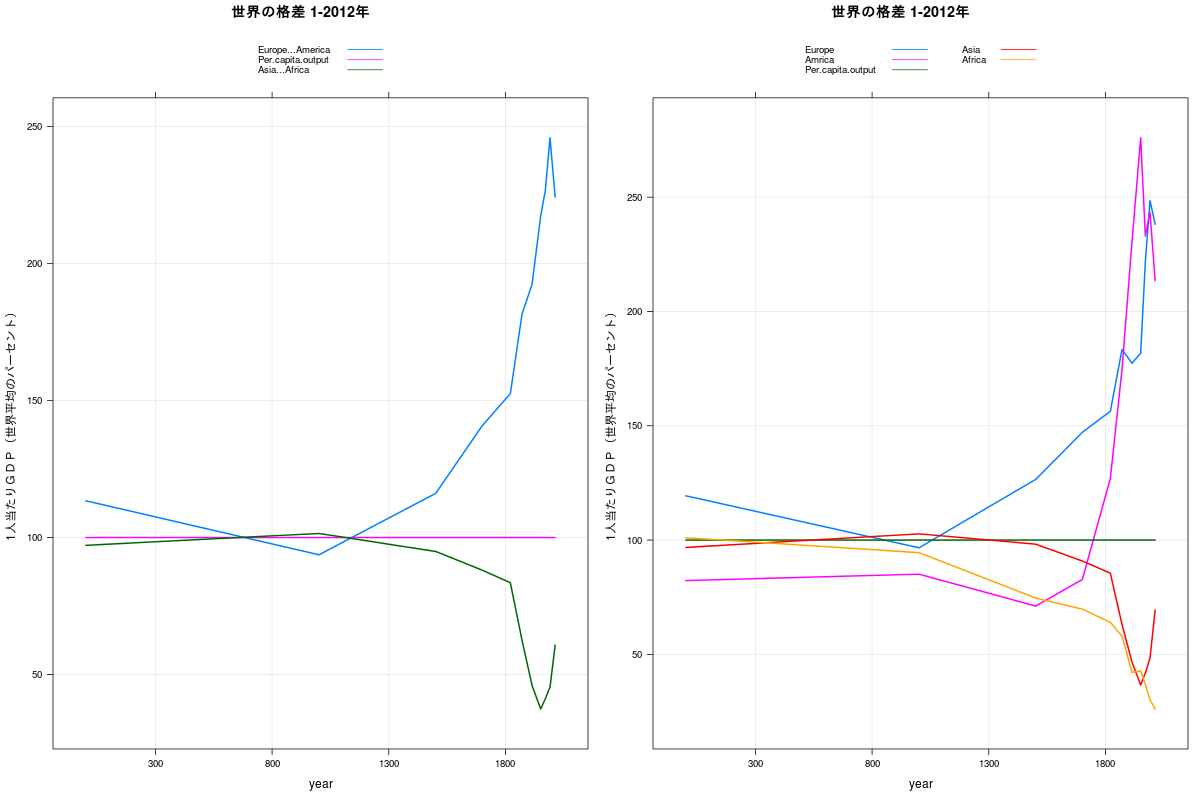
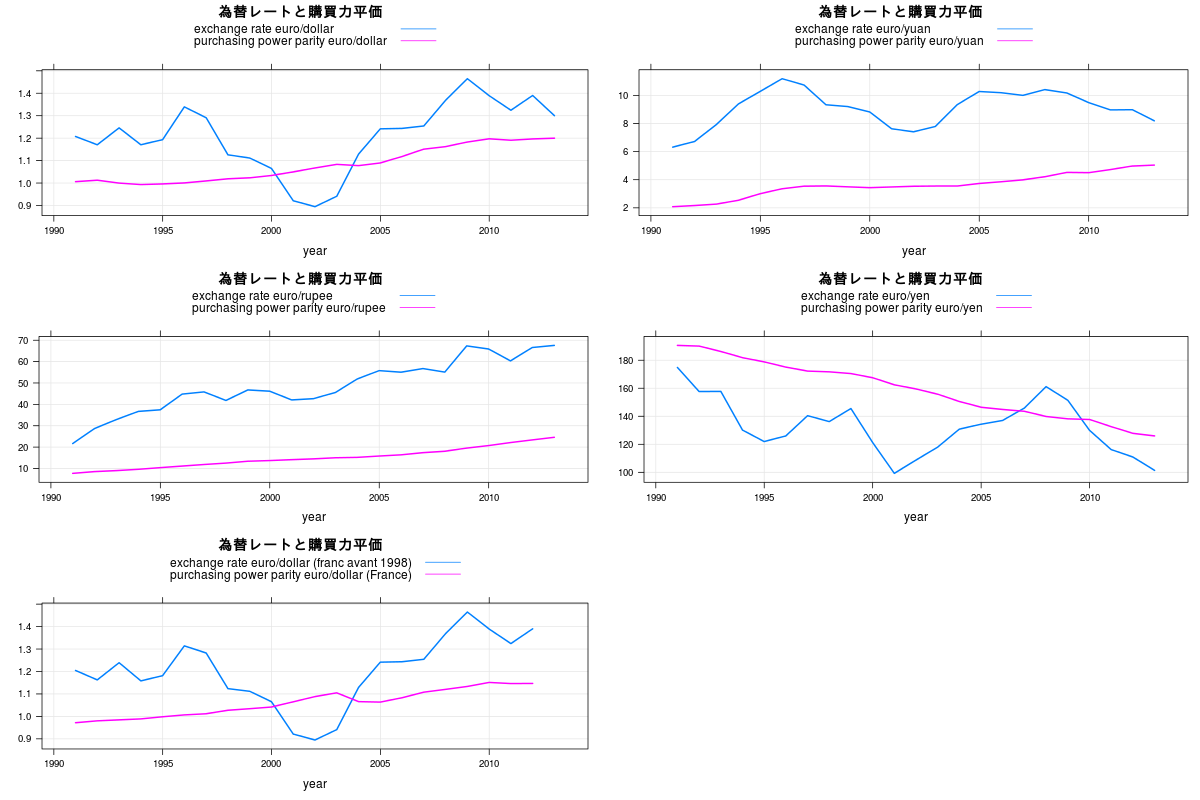
library(xts) library(Quandl) TS1_7<-Quandl("PIKETTY/TS1_7") sortlist <- order(TS1_7[,1]) dat <- TS1_7[sortlist,] TS1_7<-dat rownames(TS1_7) <- c(1:nrow(TS1_7)) library(lattice) library(gridExtra) TS1_7.xts <- as.xts(read.zoo(TS1_7)) TS<-TS1_7.xts[,c(1,3,5,7,9,10,11,15,17,19,2,4,6,8,12,13,14,16,18,20)] p1<-xyplot(TS[,c(1,11)],superpose=TRUE,xlab="year",ylab="",main="為替レートと購買力平価",lwd=2,grid = TRUE,scales = list( y = list( rot = 0 ))) p2<-xyplot(TS[,c(2,12)],superpose=TRUE,xlab="year",ylab="",main="為替レートと購買力平価",lwd=2,grid = TRUE,scales = list( y = list( rot = 0 ))) p3<-xyplot(TS[,c(3,13)],superpose=TRUE,xlab="year",ylab="",main="為替レートと購買力平価",lwd=2,grid = TRUE,scales = list( y = list( rot = 0 ))) p4<-xyplot(TS[,c(4,14)],superpose=TRUE,xlab="year",ylab="",main="為替レートと購買力平価",lwd=2,grid = TRUE,scales = list( y = list( rot = 0 ))) p5<-xyplot(TS[,c(5,15)],superpose=TRUE,xlab="year",ylab="",main="為替レートと購買力平価",lwd=2,grid = TRUE,scales = list( y = list( rot = 0 ))) grid.arrange(p1,p2,p3,p4,p5,ncol=2) p1<-xyplot(TS[,c(6,16)],superpose=TRUE,xlab="year",ylab="",main="為替レートと購買力平価",lwd=2,grid = TRUE,scales = list( y = list( rot = 0 ))) p2<-xyplot(TS[,c(7,17)],superpose=TRUE,xlab="year",ylab="",main="為替レートと購買力平価",lwd=2,grid = TRUE,scales = list( y = list( rot = 0 ))) p3<-xyplot(TS[,c(8,18)],superpose=TRUE,xlab="year",ylab="",main="為替レートと購買力平価",lwd=2,grid = TRUE,scales = list( y = list( rot = 0 ))) p4<-xyplot(TS[,c(9,19)],superpose=TRUE,xlab="year",ylab="",main="為替レートと購買力平価",lwd=2,grid = TRUE,scales = list( y = list( rot = 0 ))) p5<-xyplot(TS[,c(10,20)],superpose=TRUE,xlab="year",ylab="",main="為替レートと購買力平価",lwd=2,grid = TRUE,scales = list( y = list( rot = 0 ))) grid.arrange(p1,p2,p3,p4,p5,ncol=2)
|