OECD , ggplot2, RColorBrewer パッケージ
(参考)
OECD.Statの使い方
Reproducible and dynamic access to OECD data (pdf)
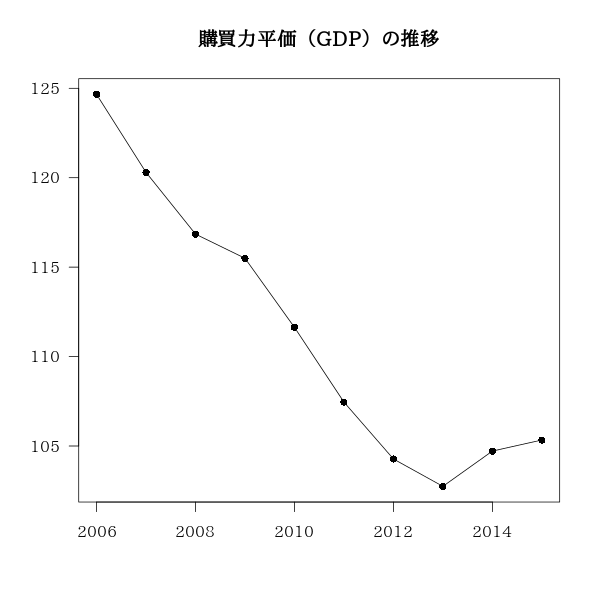
日本の2006年から2015年の購買力平価(PPPGDP)の推移を調べる。
|
|
1 LOCATION Country
2 TRANSACT Transaction
3 MEASURE Measure
4 TIME Year
5 OBS_VALUE Observation Value
6 TIME_FORMAT Time Format
7 OBS_STATUS Observation Status
8 UNIT Unit
9 POWERCODE Unit multiplier
10 REFERENCEPERIOD Reference period
今回は 1.「国・地域」(LOCATION)、2.「項目」(TRANSACT)、3.「単位」(MEASURE)、「年次」(TIME)で絞り込む
絞り込むためのidを調べる
|
|
LOCATION JPN
TRANSACT PPPGDP
MEASUREは、選択肢が一つなので指定しない
|
|
次
|
|
1 SOURCE Source
2 BRANCH Branch
3 TYPEXP Type of Expenditure
4 TYPROG Type of Programme
5 UNIT Measure (注意)ここの指定でエラー
6 COUNTRY Country
7 YEAR Year
8 OBS_VALUE Observation Value
9 TIME_FORMAT Time Format
10 OBS_STATUS Observation Status
11 UNIT Unit
12 POWERCODE Unit multiplier
13 REFERENCEPERIOD Reference period
このうち
1 SOURCE Source
2 BRANCH Branch
3 TYPEXP Type of Expenditure
4 TYPROG Type of Programme
5 UNIT Measure (注意)ここの指定でエラー
6 COUNTRY Country
7 YEAR Year (注意)2011年までのデータしかない(2016.9.11現在)
で絞り込む
|
|
データ本体入手に用いるフィルター作成ではまった。
(注意)
表示される項目が実データにあるとは限らない。
(OECDのサイトの不具合かOECDパッケージの不具合かは不明)
2011年のデータを取り出す
|
|
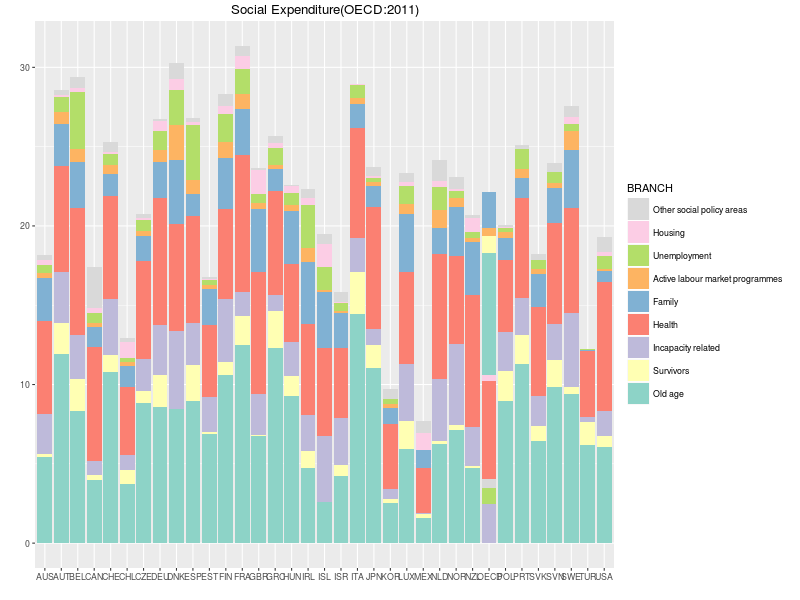
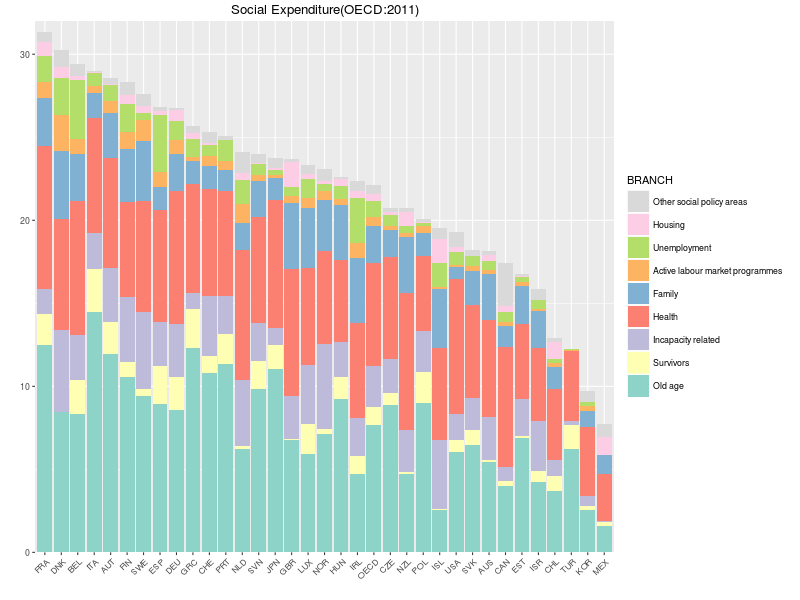
OECD平均のデータの積み重ね順がおかしい。(ggplotの不具合????)
国名はアルファベット順ではなくvalueの降順にしたい等々。
|
|
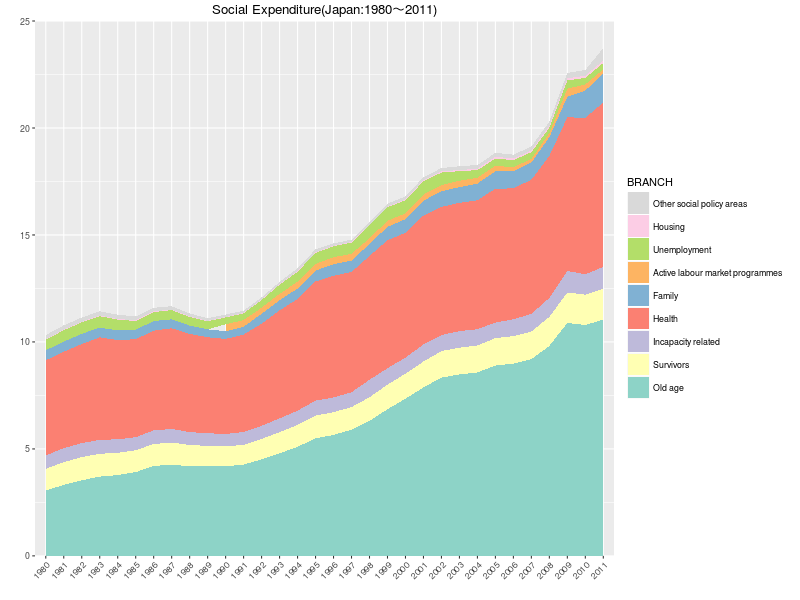
1980~2011の日本のデータ
|
|