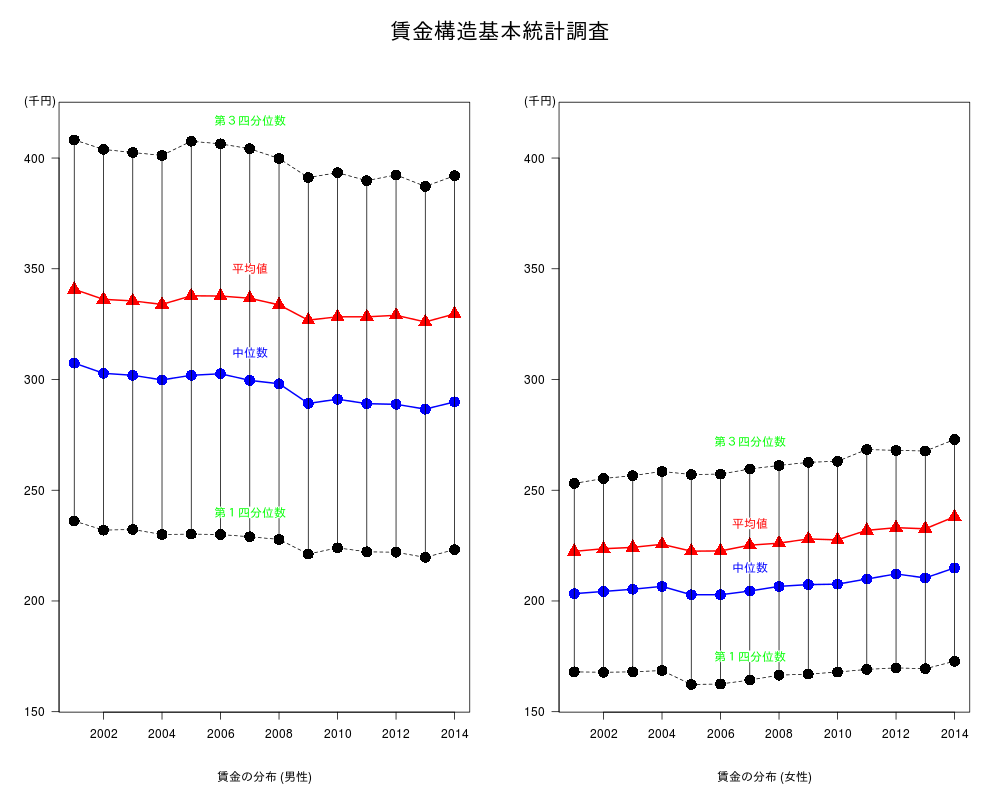
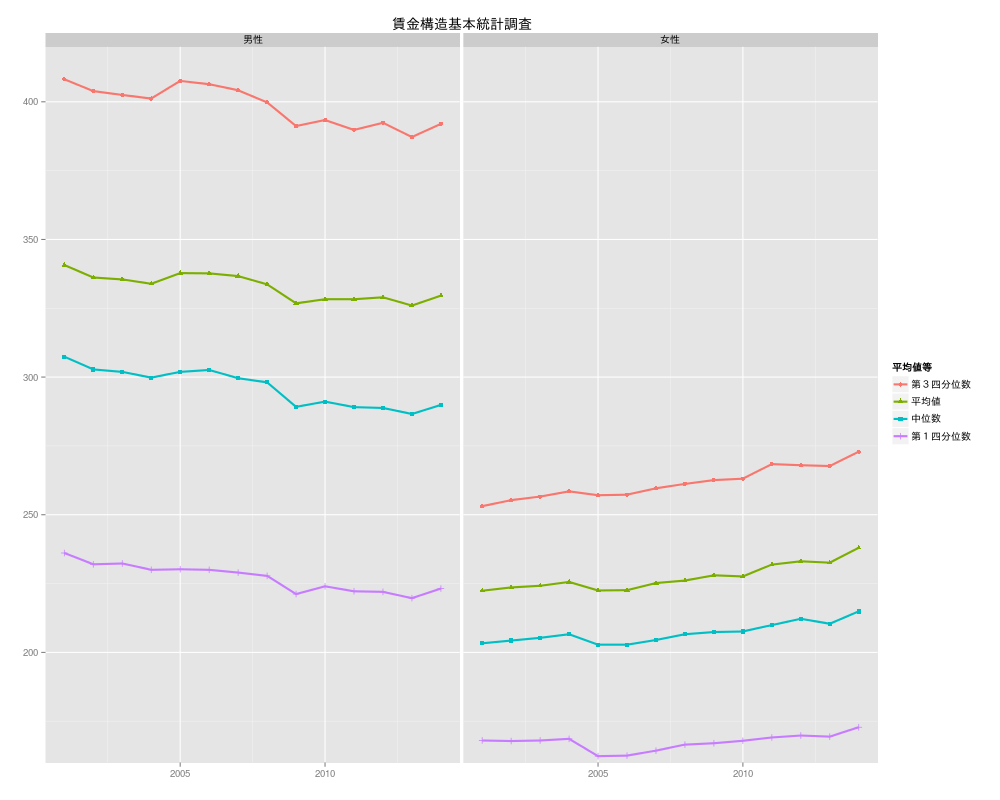
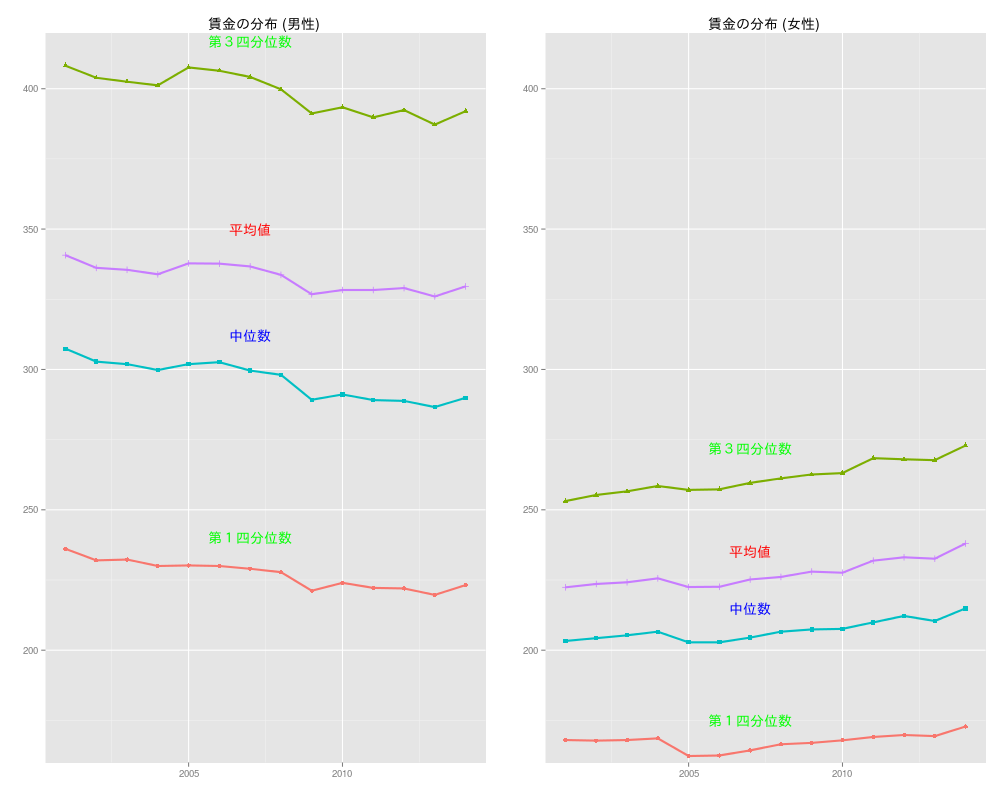
library(plotrix) wage<-read.csv("http://statrstart.github.io/data/wage.csv",fileEncoding="utf8") dm0 <- subset(wage, 性別=="男性", select=c(年,平均値等,年齢計)) sel<-c("平均値","中位数","第1四分位数","第3四分位数") dm0<-subset(dm0,平均値等 %in% sel) dm<-reshape(dm0,idvar="年",timevar="平均値等",direction = "wide") names(dm)<-gsub("年齢計.","",names(dm)) par(mfrow=c(1,2),oma=c(1,0,3,0),xpd=T) matplot(dm[,"年"],dm[,c("第1四分位数","中位数","第3四分位数")], type="o",ylim=c(160,415),pch=16,col=c("black","blue","black"), lty=c(2,1,2),lwd =c(1,2,1),cex = 2,xlab="",ylab="",las=1) lines(dm[,"年"],dm[,c("平均値")],col="red",lwd=2) points(dm[,"年"],dm[,c("平均値")],col="red",cex = 2,pch=17) for (i in 1:nrow(dm)) { segments(dm[,"年"][i],dm[,c("第1四分位数")][i],dm[,"年"][i],dm[,c("第3四分位数")][i]) } boxed.labels(2007,350,"平均値",col="red",border=0) boxed.labels(2007,312,"中位数",col="blue",border=0) boxed.labels(2007,417,"第3四分位数",col="green",border=0) boxed.labels(2007,240,"第1四分位数",col="green",border=0) text(par("usr")[1],par("usr")[4],"(千円)",pos=2,offset=0.2) title("","賃金の分布 (男性)") dw0 <- subset(wage, 性別=="女性", select=c(年,平均値等,年齢計)) dw0<-subset(dw0,平均値等 %in% sel) dw<-reshape(dw0,idvar="年",timevar="平均値等",direction = "wide") names(dw)<-gsub("年齢計.","",names(dw)) matplot(dw[,"年"],dw[,c("第1四分位数","中位数","第3四分位数")], type="o",ylim=c(160,415),pch=16,col=c("black","blue","black"), lty=c(2,1,2),lwd =c(1,2,1),cex = 2,xlab="",ylab="",las=1) lines(dw[,"年"],dw[,c("平均値")],col="red",lwd=2) points(dw[,"年"],dw[,c("平均値")],col="red",cex = 2,pch=17) for (i in 1:nrow(dw)) { segments(dw[,"年"][i],dw[,c("第1四分位数")][i],dw[,"年"][i],dw[,c("第3四分位数")][i]) } boxed.labels(2007,235,"平均値",col="red",border=0) boxed.labels(2007,215,"中位数",col="blue",border=0) boxed.labels(2007,272,"第3四分位数",col="green",border=0) boxed.labels(2007,175,"第1四分位数",col="green",border=0) text(par("usr")[1],par("usr")[4],"(千円)",pos=2,offset=0.2) title("","賃金の分布 (女性)") mtext("賃金構造基本統計調査",outer = T,side = 3,cex = 1.8,line = 0.1) par(mfrow=c(1,1),oma=c(0,0,0,0),xpd=F)
|