放送大学「心理統計法(‘17)」第10章 その1
授業ではrstanパッケージを使ってますが、MCMCpackパッケージを使ってみます。初学者ですので間違いが多々あると思います。
(Rスクリプトはここ)
早稲田大学文学部文学研究科 豊田研究室
(参考)
ベイジアンMCMCによる統計モデル
Using the ggmcmc package
Bayesian Inference With Stan ~番外編~
Exercise 2: Bayesian A/B testing using MCMC Metropolis-Hastings
政治学方法論 I
|
|
推測例1(交互作用の分析)
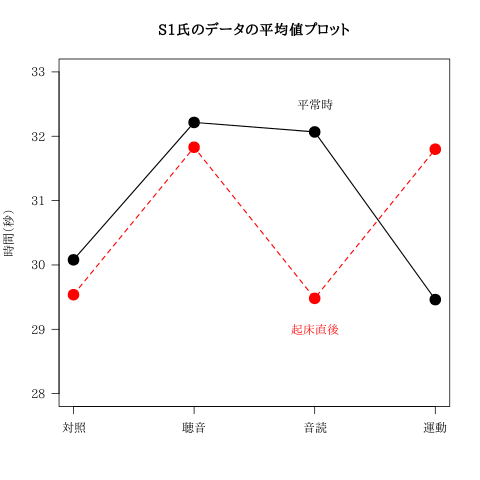
表10.1「知覚時間」データ入力
|
|
|
|
| 平常時 対照 | 平常時 聴音 | 平常時 音読 | 平常時 運動 | 起床直後 対照 | 起床直後 聴音 | 起床直後 音読 | 起床直後 運動 | |
|---|---|---|---|---|---|---|---|---|
| 平均 | 30.08 | 32.21 | 32.07 | 29.46 | 29.54 | 31.83 | 29.48 | 31.8 |
| 標準偏差 | 2.27 | 2.43 | 1.52 | 2.04 | 1.79 | 2.70 | 2.61 | 2.1 |
|
|
| 平均 | 標準偏差 | |
|---|---|---|
| 平常時 対照 | 30.08 | 2.27 |
| 平常時 聴音 | 32.21 | 2.43 |
| 平常時 音読 | 32.07 | 1.52 |
| 平常時 運動 | 29.46 | 2.04 |
| 起床直後 対照 | 29.54 | 1.79 |
| 起床直後 聴音 | 31.83 | 2.70 |
| 起床直後 音読 | 29.48 | 2.61 |
| 起床直後 運動 | 31.80 | 2.10 |
|
|
|
|
| EAP | post.sd | 2.5% | 5% | 50% | 95% | 97.5% | |
|---|---|---|---|---|---|---|---|
| mu | 30.81 | 0.26 | 30.29 | 30.37 | 30.81 | 31.24 | 31.33 |
| muA1 | -1.00 | 0.46 | -1.92 | -1.76 | -1.00 | -0.24 | -0.10 |
| muA2 | 1.21 | 0.46 | 0.30 | 0.45 | 1.21 | 1.97 | 2.12 |
| muA3 | -0.04 | 0.46 | -0.94 | -0.79 | -0.04 | 0.72 | 0.87 |
| muA4 | -0.18 | 0.46 | -1.08 | -0.93 | -0.18 | 0.58 | 0.73 |
| muB1 | 0.15 | 0.27 | -0.38 | -0.30 | 0.15 | 0.59 | 0.67 |
| muB2 | -0.15 | 0.27 | -0.67 | -0.59 | -0.15 | 0.30 | 0.38 |
| muAB11 | 0.13 | 0.46 | -0.78 | -0.63 | 0.12 | 0.88 | 1.03 |
| muAB12 | -0.13 | 0.46 | -1.03 | -0.88 | -0.12 | 0.63 | 0.78 |
| muAB21 | 0.04 | 0.46 | -0.86 | -0.71 | 0.04 | 0.80 | 0.94 |
| muAB22 | -0.04 | 0.46 | -0.94 | -0.80 | -0.04 | 0.71 | 0.86 |
| muAB31 | 1.15 | 0.46 | 0.24 | 0.39 | 1.15 | 1.91 | 2.05 |
| muAB32 | -1.15 | 0.46 | -2.05 | -1.91 | -1.15 | -0.39 | -0.24 |
| muAB41 | -1.32 | 0.46 | -2.23 | -2.08 | -1.31 | -0.55 | -0.40 |
| muAB42 | 1.32 | 0.46 | 0.40 | 0.55 | 1.31 | 2.08 | 2.23 |
| sigmaE | 2.37 | 0.20 | 2.02 | 2.07 | 2.36 | 2.73 | 2.81 |
水準とセルの効果の評価
P.147 (9.12)式
水準・交互作用の効果が0より大きい(小さい)確率
|
|
| muA1 | muA2 | muA3 | muA4 | muB1 | muB2 | muAB11 | muAB12 | muAB21 | muAB22 | muAB31 | muAB32 | muAB41 | muAB42 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 < | 0.016 | 0.995 | 0.47 | 0.348 | 0.71 | 0.29 | 0.609 | 0.391 | 0.538 | 0.462 | 0.993 | 0.007 | 0.002 | 0.998 |
| =< 0 | 0.984 | 0.005 | 0.53 | 0.652 | 0.29 | 0.71 | 0.391 | 0.609 | 0.462 | 0.538 | 0.007 | 0.993 | 0.998 | 0.002 |
要因の効果の評価
|
|
| EAP | post.sd | 2.5% | 5% | 50% | 95% | 97.5% | |
|---|---|---|---|---|---|---|---|
| sigmaA | 0.880 | 0.251 | 0.398 | 0.471 | 0.876 | 1.299 | 1.386 |
| sigmaB | 0.245 | 0.183 | 0.010 | 0.019 | 0.208 | 0.595 | 0.678 |
| sigmaAB | 0.956 | 0.255 | 0.467 | 0.543 | 0.952 | 1.383 | 1.470 |
| sigmaE | 2.375 | 0.203 | 2.018 | 2.069 | 2.360 | 2.732 | 2.812 |
| etaA2 | 0.109 | 0.053 | 0.022 | 0.031 | 0.104 | 0.205 | 0.226 |
| etaB2 | 0.012 | 0.016 | 0.000 | 0.000 | 0.006 | 0.046 | 0.058 |
| etaAB2 | 0.128 | 0.058 | 0.031 | 0.042 | 0.123 | 0.231 | 0.253 |
| etat2 | 0.249 | 0.070 | 0.116 | 0.135 | 0.248 | 0.366 | 0.388 |
| deltaA | 0.373 | 0.108 | 0.164 | 0.196 | 0.371 | 0.553 | 0.589 |
| deltaB | 0.103 | 0.077 | 0.004 | 0.008 | 0.088 | 0.251 | 0.285 |
| deltaAB | 0.405 | 0.111 | 0.192 | 0.225 | 0.404 | 0.590 | 0.626 |
セル平均の事後分布
|
|
| EAP | post.sd | 2.5% | 5% | 50% | 95% | 97.5% | |
|---|---|---|---|---|---|---|---|
| mu11 | 30.08 | 0.76 | 28.59 | 28.84 | 30.08 | 31.32 | 31.57 |
| mu12 | 29.54 | 0.75 | 28.07 | 28.31 | 29.54 | 30.78 | 31.02 |
| mu21 | 32.21 | 0.75 | 30.74 | 30.98 | 32.21 | 33.44 | 33.68 |
| mu22 | 31.83 | 0.75 | 30.35 | 30.60 | 31.83 | 33.07 | 33.32 |
| mu31 | 32.07 | 0.75 | 30.59 | 30.83 | 32.07 | 33.31 | 33.56 |
| mu32 | 29.48 | 0.75 | 28.01 | 28.25 | 29.48 | 30.72 | 30.97 |
| mu41 | 29.46 | 0.76 | 27.98 | 28.22 | 29.46 | 30.69 | 30.95 |
| mu42 | 31.80 | 0.75 | 30.31 | 30.56 | 31.80 | 33.04 | 33.28 |
セル平均mu_jkは、mu_j’k’より大きい
|
|
| mu11 | mu12 | mu21 | mu22 | mu31 | mu32 | mu41 | mu42 | |
|---|---|---|---|---|---|---|---|---|
| mu11 | 0.000 | 0.697 | 0.024 | 0.050 | 0.031 | 0.716 | 0.720 | 0.054 |
| mu12 | 0.303 | 0.000 | 0.007 | 0.018 | 0.009 | 0.523 | 0.530 | 0.017 |
| mu21 | 0.976 | 0.993 | 0.000 | 0.639 | 0.555 | 0.994 | 0.994 | 0.649 |
| mu22 | 0.950 | 0.982 | 0.361 | 0.000 | 0.412 | 0.986 | 0.986 | 0.512 |
| mu31 | 0.969 | 0.991 | 0.445 | 0.588 | 0.000 | 0.992 | 0.992 | 0.600 |
| mu32 | 0.284 | 0.477 | 0.006 | 0.014 | 0.008 | 0.000 | 0.506 | 0.016 |
| mu41 | 0.280 | 0.470 | 0.006 | 0.014 | 0.008 | 0.494 | 0.000 | 0.015 |
| mu42 | 0.946 | 0.983 | 0.351 | 0.488 | 0.400 | 0.984 | 0.985 | 0.000 |
特に興味のある2セル間の比較
「音読」における「平常時」ー「起床直後」の差の推測
|
|
| EAP | post.sd | 2.5% | 5% | 50% | 95% | 97.5% | |
|---|---|---|---|---|---|---|---|
| mu31_mu32 | 2.587 | 1.068 | 0.485 | 0.843 | 2.584 | 4.344 | 4.688 |
| delta | 1.097 | 0.458 | 0.202 | 0.349 | 1.097 | 1.852 | 1.997 |
| U3 | 0.841 | 0.105 | 0.580 | 0.636 | 0.864 | 0.968 | 0.977 |
| pid | 0.770 | 0.095 | 0.557 | 0.597 | 0.781 | 0.905 | 0.921 |
| pi1 | 0.675 | 0.110 | 0.441 | 0.482 | 0.683 | 0.842 | 0.865 |
「起床直後」における「運動」ー「音読」の差の推測
|
|
| EAP | post.sd | 2.5% | 5% | 50% | 95% | 97.5% | |
|---|---|---|---|---|---|---|---|
| mu42_mu32 | 2.321 | 1.068 | 0.232 | 0.575 | 2.316 | 4.082 | 4.410 |
| delta | 0.984 | 0.456 | 0.096 | 0.239 | 0.982 | 1.735 | 1.876 |
| U3 | 0.815 | 0.114 | 0.538 | 0.594 | 0.837 | 0.959 | 0.970 |
| pid | 0.746 | 0.099 | 0.527 | 0.567 | 0.756 | 0.890 | 0.908 |
| pi1 | 0.647 | 0.113 | 0.410 | 0.450 | 0.653 | 0.821 | 0.846 |