conjoint( tea データ) , ggplot2 , knitr , qdapTools パッケージ
conjointパッケージのデータ tea をコンジョイント分析
|
|
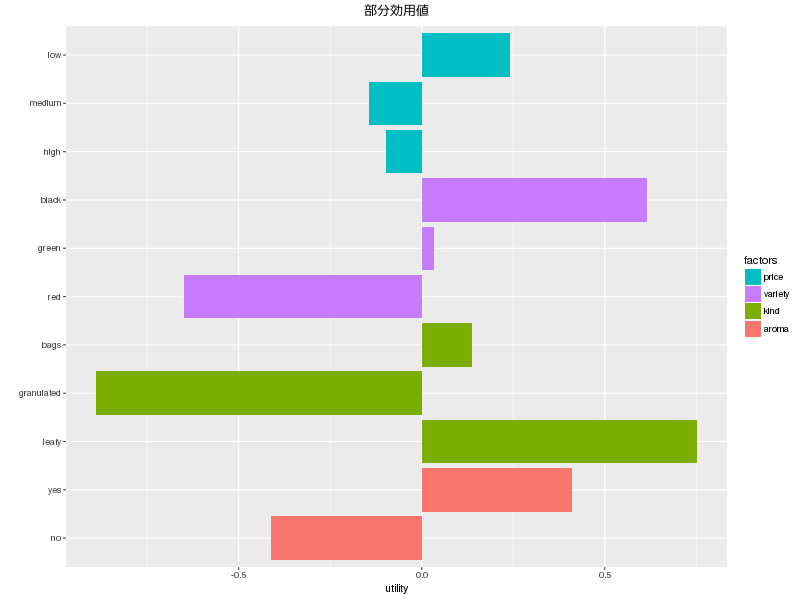
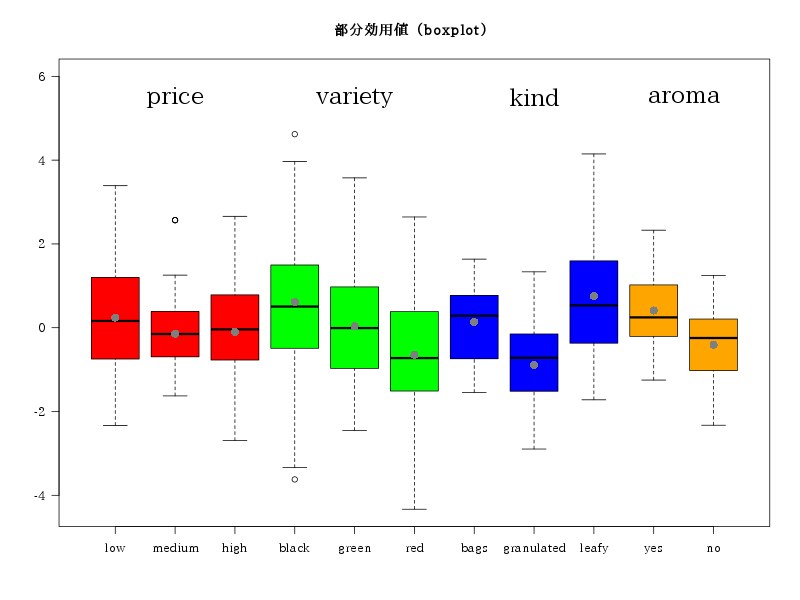
相関行列
| price | variety | kind | aroma | |
|---|---|---|---|---|
| price | 1.0000000 | -0.0900000 | 0 | -0.0474342 |
| variety | -0.0900000 | 1.0000000 | 0 | 0.0474342 |
| kind | 0.0000000 | 0.0000000 | 1 | 0.0000000 |
| aroma | -0.0474342 | 0.0474342 | 0 | 1.0000000 |
|
|
|
|
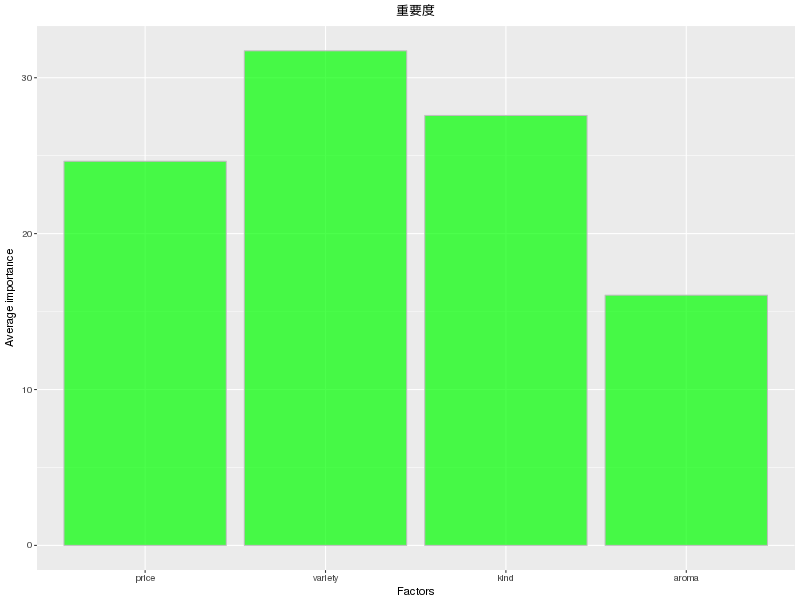
重要度得点
| imp | factors | |
|---|---|---|
| price | 24.64 | price |
| variety | 31.73 | variety |
| kind | 27.58 | kind |
| aroma | 16.05 | aroma |
|
|
|
|
|
|
|
|
[1] 1 2 3 2 2 1 2 1 2 3 3 3 1 1 1 1 2 1 2 1 1 3 1 2 2 1 2 2 2 2 1 2 1 2 3 3 3
[38] 1 1 1 1 2 1 2 1 1 3 1 1 1 2 1 1 1 2 2 1 2 1 2 1 1 2 2 1 2 1 1 1 2 2 1 1 2
[75] 3 2 2 1 2 1 2 2 2 3 1 1 1 1 2 1 2 1 2 1 1 3 1 1 2 3
|
|
予測値の算出 (全組み合わせ)
|
|
| price | variety | kind | aroma | Score |
|---|---|---|---|---|
| low | black | bags | yes | 4.956 |
| medium | black | bags | yes | 4.573 |
| high | black | bags | yes | 4.619 |
| low | green | bags | yes | 4.376 |
| medium | green | bags | yes | 3.993 |
| high | green | bags | yes | 4.039 |
| low | red | bags | yes | 3.691 |
| medium | red | bags | yes | 3.308 |
| high | red | bags | yes | 3.354 |
| low | black | granulated | yes | 3.929 |
| medium | black | granulated | yes | 3.546 |
| high | black | granulated | yes | 3.592 |
| low | green | granulated | yes | 3.349 |
| medium | green | granulated | yes | 2.966 |
| high | green | granulated | yes | 3.012 |
| low | red | granulated | yes | 2.665 |
| medium | red | granulated | yes | 2.281 |
| high | red | granulated | yes | 2.327 |
| low | black | leafy | yes | 5.572 |
| medium | black | leafy | yes | 5.189 |
| high | black | leafy | yes | 5.235 |
| low | green | leafy | yes | 4.992 |
| medium | green | leafy | yes | 4.609 |
| high | green | leafy | yes | 4.655 |
| low | red | leafy | yes | 4.307 |
| medium | red | leafy | yes | 3.924 |
| high | red | leafy | yes | 3.970 |
| low | black | bags | no | 4.135 |
| medium | black | bags | no | 3.751 |
| high | black | bags | no | 3.797 |
| low | green | bags | no | 3.555 |
| medium | green | bags | no | 3.171 |
| high | green | bags | no | 3.217 |
| low | red | bags | no | 2.870 |
| medium | red | bags | no | 2.487 |
| high | red | bags | no | 2.533 |
| low | black | granulated | no | 3.108 |
| medium | black | granulated | no | 2.725 |
| high | black | granulated | no | 2.771 |
| low | green | granulated | no | 2.528 |
| medium | green | granulated | no | 2.145 |
| high | green | granulated | no | 2.191 |
| low | red | granulated | no | 1.843 |
| medium | red | granulated | no | 1.460 |
| high | red | granulated | no | 1.506 |
| low | black | leafy | no | 4.751 |
| medium | black | leafy | no | 4.367 |
| high | black | leafy | no | 4.413 |
| low | green | leafy | no | 4.171 |
| medium | green | leafy | no | 3.787 |
| high | green | leafy | no | 3.833 |
| low | red | leafy | no | 3.486 |
| medium | red | leafy | no | 3.103 |
| high | red | leafy | no | 3.149 |
シミュレーションの選好確率(各シミュレーション ケースが最も好ましいものとして選択される確率)
conjoint package の tea data の tsimp
|
|
| price | variety | kind | aroma | MaxModel | BTLModel | LogitModel |
|---|---|---|---|---|---|---|
| high | green | granulated | no | 11 | 14.11 | 19.99 |
| low | red | bags | yes | 28 | 30.77 | 27.60 |
| medium | red | leafy | no | 26 | 25.74 | 25.30 |
| high | black | granulated | yes | 35 | 29.39 | 27.12 |
conjoint パッケージとは最大効用値モデル以外は結果が一致しない!!!
|
|
TotalUtility MaxUtility BTLmodel LogitModel
1 2,19 11 18,85 13,04
2 3,69 28 28,96 34,84
3 3,10 26 30,14 35,79
4 3,59 35 22,06 16,33
シミュレーションの選好確率(全組み合わせ)
予測値の算出 (全組み合わせ)で作成した codefullを使う
|
|
| price | variety | kind | aroma | MaxModel | BTLModel | LogitModel |
|---|---|---|---|---|---|---|
| low | black | bags | yes | 7.55 | 2.39 | 2.13 |
| medium | black | bags | yes | 2.83 | 2.31 | 2.06 |
| high | black | bags | yes | 8.49 | 2.31 | 2.09 |
| low | green | bags | yes | 5.66 | 2.10 | 1.97 |
| medium | green | bags | yes | 0.00 | 2.02 | 1.90 |
| high | green | bags | yes | 0.00 | 2.01 | 1.91 |
| low | red | bags | yes | 0.00 | 1.87 | 1.85 |
| medium | red | bags | yes | 0.00 | 1.79 | 1.79 |
| high | red | bags | yes | 0.94 | 1.78 | 1.81 |
| low | black | granulated | yes | 0.00 | 2.00 | 1.91 |
| medium | black | granulated | yes | 0.00 | 1.92 | 1.87 |
| high | black | granulated | yes | 0.00 | 1.92 | 1.88 |
| low | green | granulated | yes | 0.00 | 1.71 | 1.77 |
| medium | green | granulated | yes | 2.83 | 1.62 | 1.73 |
| high | green | granulated | yes | 0.00 | 1.62 | 1.73 |
| low | red | granulated | yes | 0.00 | 1.48 | 1.66 |
| medium | red | granulated | yes | 0.94 | 1.39 | 1.62 |
| high | red | granulated | yes | 0.00 | 1.39 | 1.63 |
| low | black | leafy | yes | 11.32 | 2.67 | 2.27 |
| medium | black | leafy | yes | 0.94 | 2.59 | 2.21 |
| high | black | leafy | yes | 2.83 | 2.58 | 2.23 |
| low | green | leafy | yes | 9.43 | 2.37 | 2.13 |
| medium | green | leafy | yes | 0.00 | 2.29 | 2.06 |
| high | green | leafy | yes | 3.77 | 2.29 | 2.08 |
| low | red | leafy | yes | 0.00 | 2.14 | 1.99 |
| medium | red | leafy | yes | 2.83 | 2.06 | 1.94 |
| high | red | leafy | yes | 7.55 | 2.06 | 1.95 |
| low | black | bags | no | 0.00 | 2.05 | 1.94 |
| medium | black | bags | no | 0.00 | 1.97 | 1.89 |
| high | black | bags | no | 4.72 | 1.96 | 1.89 |
| low | green | bags | no | 3.77 | 1.75 | 1.80 |
| medium | green | bags | no | 0.00 | 1.67 | 1.74 |
| high | green | bags | no | 0.00 | 1.67 | 1.73 |
| low | red | bags | no | 3.77 | 1.52 | 1.70 |
| medium | red | bags | no | 2.83 | 1.44 | 1.66 |
| high | red | bags | no | 0.00 | 1.44 | 1.65 |
| low | black | granulated | no | 0.00 | 1.66 | 1.75 |
| medium | black | granulated | no | 0.00 | 1.58 | 1.72 |
| high | black | granulated | no | 0.94 | 1.57 | 1.71 |
| low | green | granulated | no | 0.00 | 1.36 | 1.63 |
| medium | green | granulated | no | 0.00 | 1.28 | 1.60 |
| high | green | granulated | no | 0.94 | 1.28 | 1.58 |
| low | red | granulated | no | 0.00 | 1.13 | 1.53 |
| medium | red | granulated | no | 0.00 | 1.05 | 1.51 |
| high | red | granulated | no | 0.00 | 1.05 | 1.49 |
| low | black | leafy | no | 1.89 | 2.32 | 2.07 |
| medium | black | leafy | no | 6.60 | 2.24 | 2.03 |
| high | black | leafy | no | 0.00 | 2.24 | 2.02 |
| low | green | leafy | no | 1.89 | 2.02 | 1.95 |
| medium | green | leafy | no | 0.94 | 1.94 | 1.90 |
| high | green | leafy | no | 0.00 | 1.94 | 1.89 |
| low | red | leafy | no | 0.00 | 1.79 | 1.82 |
| medium | red | leafy | no | 2.83 | 1.71 | 1.79 |
| high | red | leafy | no | 0.94 | 1.71 | 1.78 |
MaxModel が整数ではない?
|
|
[1] 106
同点が6個ある。