放送大学「心理統計法(‘17)」第13章
授業ではrstanパッケージを使ってますが、MCMCpackパッケージを使ってみます。初学者ですので間違いが多々あると思います。
(Rスクリプトはここ)
早稲田大学文学部文学研究科 豊田研究室
(参考)
ベイジアンMCMCによる統計モデル
Using the ggmcmc package
Bayesian Inference With Stan ~番外編~
Exercise 2: Bayesian A/B testing using MCMC Metropolis-Hastings
政治学方法論 I
|
|
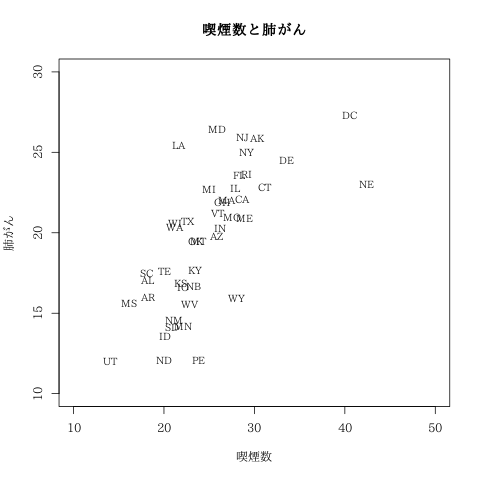
|
|
| EAP | post.sd | 2.5% | 5% | 50% | 95% | 97.5% | |
|---|---|---|---|---|---|---|---|
| a(切片) | 6.474 | 2.224 | 2.100 | 2.820 | 6.479 | 10.112 | 10.853 |
| b(回帰係数) | 0.529 | 0.087 | 0.358 | 0.386 | 0.529 | 0.672 | 0.700 |
| sigmaE(誤差sd) | 3.161 | 0.357 | 2.556 | 2.636 | 3.129 | 3.794 | 3.949 |
予測値の事後分布
|
|
予測値の分散の事後分布
|
|
決定係数
(13.16)式
|
|
| EAP | post.sd | 2.5% | 5% | 50% | 95% | 97.5% | |
|---|---|---|---|---|---|---|---|
| a(切片) | 6.474 | 2.224 | 2.100 | 2.820 | 6.479 | 10.112 | 10.853 |
| b(回帰係数) | 0.529 | 0.087 | 0.358 | 0.386 | 0.529 | 0.672 | 0.700 |
| sigmaE(誤差sd) | 3.161 | 0.357 | 2.556 | 2.636 | 3.129 | 3.794 | 3.949 |
| eta2 | 0.464 | 0.097 | 0.254 | 0.292 | 0.471 | 0.611 | 0.631 |
事後予測分布
(13.17)式
|
|
残差
|
|
残差の点推定値
|
|
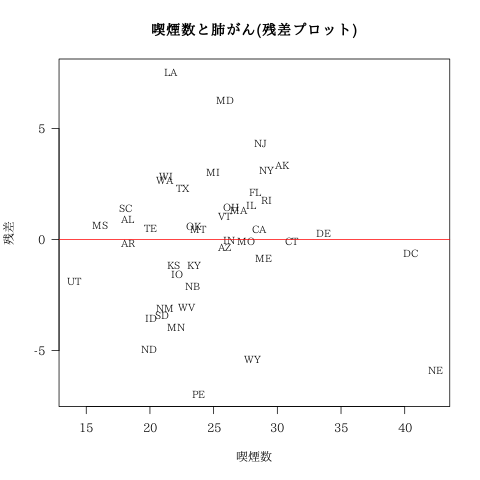
回帰直線
任意の予測変数の事後分布
(13.13)式
8から52まで2つおき
|
|
任意の予測変数の事後予測分布
(13.18)式
8から52まで2つおき
|
|
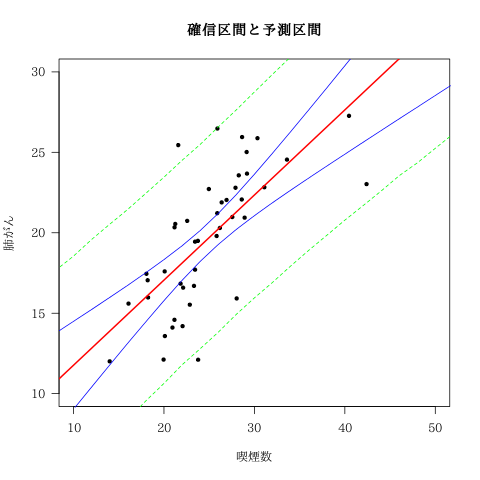
予測値・残差・事後標準偏差・確信区間・予測区間
州名 : smoke$STATE , 予測値の事後分布 : yhat , 事後予測分布 : yaste , 残差 : eihat
|
|
| 予測値 | 残差 | post.sd | 確信95%(下) | 確信95%(上) | sd | 予測95%(下) | 予測95%(上) | |
|---|---|---|---|---|---|---|---|---|
| AK | 22.53 | 3.35 | 0.67 | 21.20 | 23.86 | 3.23 | 16.14 | 28.88 |
| AL | 16.10 | 0.95 | 0.76 | 14.60 | 17.60 | 3.27 | 9.70 | 22.54 |
| AR | 16.12 | -0.14 | 0.76 | 14.63 | 17.61 | 3.27 | 9.67 | 22.59 |
| AZ | 20.13 | -0.33 | 0.49 | 19.18 | 21.10 | 3.21 | 13.83 | 26.46 |
| CA | 21.60 | 0.47 | 0.58 | 20.47 | 22.75 | 3.23 | 15.20 | 27.93 |
| CT | 22.93 | -0.10 | 0.72 | 21.51 | 24.35 | 3.25 | 16.52 | 29.24 |
| DC | 27.88 | -0.61 | 1.43 | 25.05 | 30.70 | 3.48 | 21.06 | 34.75 |
| DE | 24.25 | 0.30 | 0.89 | 22.49 | 26.01 | 3.30 | 17.76 | 30.74 |
| FL | 21.43 | 2.14 | 0.56 | 20.33 | 22.54 | 3.24 | 15.06 | 27.81 |
| ID | 17.11 | -3.53 | 0.64 | 15.84 | 18.37 | 3.24 | 10.74 | 23.49 |
| IL | 21.24 | 1.56 | 0.55 | 20.17 | 22.32 | 3.23 | 14.90 | 27.59 |
| IN | 20.32 | -0.02 | 0.49 | 19.36 | 21.30 | 3.23 | 13.97 | 26.68 |
| IO | 18.18 | -1.59 | 0.54 | 17.11 | 19.24 | 3.21 | 11.84 | 24.47 |
| KS | 18.03 | -1.19 | 0.55 | 16.94 | 19.12 | 3.22 | 11.70 | 24.44 |
| KY | 18.87 | -1.16 | 0.50 | 17.90 | 19.86 | 3.22 | 12.52 | 25.23 |
| LA | 17.89 | 7.56 | 0.56 | 16.78 | 19.00 | 3.23 | 11.54 | 24.25 |
| MA | 20.72 | 1.32 | 0.51 | 19.71 | 21.72 | 3.23 | 14.36 | 27.13 |
| MD | 20.18 | 6.30 | 0.49 | 19.22 | 21.15 | 3.22 | 13.84 | 26.47 |
| ME | 21.77 | -0.83 | 0.59 | 20.61 | 22.95 | 3.24 | 15.34 | 28.16 |
| MI | 19.68 | 3.04 | 0.48 | 18.74 | 20.63 | 3.20 | 13.33 | 25.98 |
| MN | 18.14 | -3.94 | 0.54 | 17.08 | 19.21 | 3.23 | 11.81 | 24.48 |
| MO | 21.05 | -0.07 | 0.53 | 20.01 | 22.11 | 3.23 | 14.73 | 27.45 |
| MS | 14.98 | 0.62 | 0.91 | 13.19 | 16.77 | 3.30 | 8.47 | 21.50 |
| MT | 19.04 | 0.46 | 0.49 | 18.08 | 20.01 | 3.22 | 12.74 | 25.39 |
| NB | 18.81 | -2.11 | 0.50 | 17.83 | 19.80 | 3.22 | 12.46 | 25.16 |
| ND | 17.03 | -4.91 | 0.65 | 15.75 | 18.31 | 3.25 | 10.60 | 23.38 |
| NE | 28.91 | -5.88 | 1.59 | 25.76 | 32.04 | 3.57 | 21.90 | 35.99 |
| NJ | 21.63 | 4.32 | 0.58 | 20.49 | 22.77 | 3.24 | 15.24 | 28.01 |
| NM | 17.67 | -3.08 | 0.58 | 16.52 | 18.82 | 3.24 | 11.29 | 24.05 |
| NY | 21.89 | 3.13 | 0.60 | 20.70 | 23.09 | 3.23 | 15.50 | 28.28 |
| OH | 20.43 | 1.46 | 0.50 | 19.46 | 21.41 | 3.22 | 14.11 | 26.79 |
| OK | 18.87 | 0.58 | 0.50 | 17.90 | 19.86 | 3.22 | 12.52 | 25.21 |
| PE | 19.05 | -6.94 | 0.49 | 18.09 | 20.03 | 3.21 | 12.72 | 25.37 |
| RI | 21.91 | 1.77 | 0.61 | 20.72 | 23.11 | 3.24 | 15.51 | 28.25 |
| SC | 16.03 | 1.42 | 0.77 | 14.51 | 17.54 | 3.27 | 9.61 | 22.45 |
| SD | 17.55 | -3.44 | 0.60 | 16.38 | 18.73 | 3.24 | 11.15 | 23.93 |
| TE | 17.10 | 0.50 | 0.64 | 15.83 | 18.36 | 3.24 | 10.69 | 23.50 |
| TX | 18.41 | 2.33 | 0.52 | 17.39 | 19.45 | 3.23 | 12.07 | 24.77 |
| UT | 13.88 | -1.87 | 1.07 | 11.78 | 15.98 | 3.36 | 7.27 | 20.50 |
| VT | 20.17 | 1.05 | 0.49 | 19.21 | 21.14 | 3.22 | 13.85 | 26.49 |
| WA | 17.67 | 2.67 | 0.58 | 16.52 | 18.83 | 3.23 | 11.26 | 24.02 |
| WI | 17.72 | 2.83 | 0.58 | 16.57 | 18.86 | 3.24 | 11.30 | 24.05 |
| WV | 18.57 | -3.04 | 0.52 | 17.56 | 19.58 | 3.21 | 12.20 | 24.86 |
| WY | 21.31 | -5.39 | 0.55 | 20.22 | 22.40 | 3.23 | 14.94 | 27.66 |